Vor einigen Wochen habe ich bereits in einem unserer Wochenrückblicke über das Thema Crawl Optimization geschrieben. Heute möchte ich mich intensiver mit dem Thema auseinandersetzen und euch ein paar nützliche Tipps und Tricks an die Hand geben, wie man den Google-Bot zumindest ein Stück weit steuern und auf die richtigen bzw. wichtigen Seiten schicken kann. Los geht’s!
Crawl Optimization – warum ist sie wichtig?
Das World Wide Web enthält eine unvorstellbare Menge an Informationen auf unzähligen Seiten – Tendenz steigend. Als Suchmaschine ist Google bestrebt, dem Nutzer zu jeder Suchanfrage das passendste Ergebnis aus diesem riesigen Informationsangebot zu liefern. Dazu schickt die Suchmaschine Crawler in die Untiefen des Webs, die Webseiten auslesen und erfassen, sodass sie in den Index aufgenommen werden und in den Google-SERPs zu passenden Suchanfragen ranken können.
Welche Faktoren bestimmen, wie der Google-Bot eine Seite crawlt?
Bedingt durch die große Anzahl an Websites im World Wide Web ist es verständlich, dass Google für jede Domain nur eine begrenzte Zeit aufbringen kann, um diese zu crawlen und Unterseiten zu erfassen. Doch wovon hängt es ab, wie der Crawler eine Website ausliest? Hier spielen drei Aspekte eine Rolle:
- Welche Seiten werden gecrawlt? Das hängt u.a. von der Anzahl der Backlinks und der Anzahl der internen Links ab, die auf die jeweilige Unters
 eite verweisen.
eite verweisen. - Wie viele Seiten werden gecrawlt? Das wird durch das Crawl-Budget bestimmt. Jede Domain verfügt über ein individuelles Crawl-Budget, das festlegt, wieviel Zeit der Crawler auf der Domain aufbringt bzw. wie viele Unterseiten er ausliest. Laut Matt Cutts hängt die Anzahl der Seiten, die der Google-Bot auf einer Domain crawlt, vor allem von deren PageRank ab.
- Wie häufig besucht der Google-Bot die Website? Das hängt u.a. davon ab, wie häufig die Website aktualisiert wird bzw. neuen Content veröffentlicht sowie von der Aktualität von Erwähnungen, Social Signals und externen Links.
In Anbetracht dieses begrenzten Crawl-Budgets ist es umso wichtiger, dass der Crawler der Suchmaschine die wichtigen Seiten der Domain crawlt und keine Zeit auf unwichtigen Seiten verschwendet. Und genau das ist das Ziel der Crawl Optimization. Es geht darum, insgesamt eine möglichst große Zahl an Unterseiten crawlen zu lassen, unwichtige Seiten vom Crawling auszuschließen und mögliche „Sackgassen“ wie schlechte 404-Fehlerseiten aufzulösen, sodass der Google-Bot hier nicht unnötig Zeit aufwendet.
Neben dem Crawl-Budget verfügt jede Domain über ein individuelles Index-Budget, das bestimmt, wie viele URLs einer Domain maximal in den Index von Google aufgenommen werden. Gerade bei großen Web-Auftritten mit sehr vielen URLs kann es sinnvoll sein, im Zuge der Crawl Optimization unwichtige Seiten von der Indexierung auszuschließen, um das Index-Budget bestmöglich auszuschöpfen.
Hintergrund: Caffeine und der Google-Index
Im Juni 2010 implementierte Google mit Caffeine eine neue Art, Web-Inhalte zu indexieren. Caffeine hatte große Auswirkungen auf die Schnelligkeit, mit der Google Seiten crawlen und indexieren kann.
Vor Caffeine bestand der Google-Index aus verschiedenen Schichten, die in unterschiedlichen Zeitabständen aktualisiert wurden. Um eine dieser Schichten auf den neuesten Stand zu bringen, wurde das gesamte Web analysiert, was dazu führte, dass es häufig eine recht große Zeitspanne zwischen dem Finden einer neuen Seite und der tatsächlichen Indexierung gab.
Mit dem neuen Indexierungssystem Caffeine wird das Web in kleinen Portionen analysiert und der Index kontinuierlich und global erneuert. Die Crawl-Geschwindigkeit stimmt jetzt mit der Indexierungsgeschwindigkeit überein.
Diese Optimierung des Indexierungsvorgangs führte allerdings nicht dazu, dass jetzt viel mehr Seiten in den Index aufgenommen werden. Vielmehr ist es oft so, dass dieselben Seiten häufiger gecrawlt werden. Dies gilt vor allem für besonders wichtige und große Websites, denn Google strebt an, dass diese wichtigsten Seiten möglichst aktuell im Index sind.
Seiten, die regelmäßig gecrawlt werden, ranken in der Regel auch gut. Im Umkehrschluss heißt das: Seiten, die nur unregelmäßig gecrawlt werden, ranken dementsprechend schlechter. Auch hier wird also wieder deutlich: Crawl Optimization ist ein wichtiger Faktor, damit die wichtigen Seiten in den Index gelangen und erfolgreich ranken können.
Die Basis: eine flache Seitenarchitektur
Bevor man sich an die Umsetzung technischer Tricks macht, die den Suchmaschinen-Crawler auf die richtigen Seiten lenkt, sollte man zunächst einen Blick auf die Informationsarchitektur der Website werfen. Denn eines ist klar: Eine flache und übersichtliche Struktur, bei der jede Unterseite mittels weniger Klicks erreicht werden kann, ist nicht nur vorteilhaft für den User, sondern auch für den Crawler.
Das Thema Informationsarchitektur habe ich in einem meiner letzten Fachartikel bereits behandelt. Deshalb möchte ich an dieser Stelle nicht im Detail darauf eingehen, sondern nur die wichtigsten Aspekte kurz aufführen.
Auf moz.com stellt Rand Fishkin einige interessante Grafiken vor, die veranschaulichen, wie man die Webseitenarchitektur gestalten sollte, damit möglichst viele Unterseiten gecrawlt werden und in den Index gelangen.
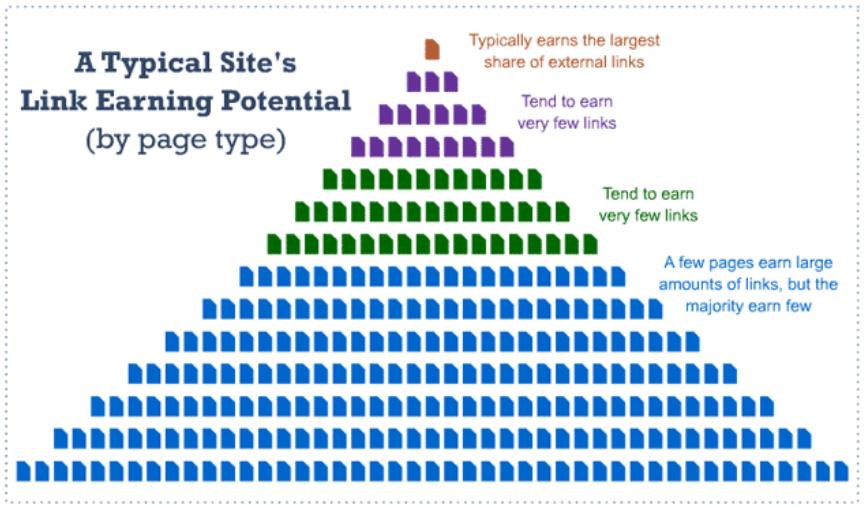
Diese Grafik zeigt, wie viele Links die verschiedenen Arten von Unterseiten in der Regel bekommen. Die orangefarbene Seite ist die Homepage und verfügt in der Regel über die größte Anzahl an Backlinks. Die Kategorieseiten (violett) und die Unterkategorieseiten (grün) bekommen meist sehr wenige Backlinks. Der Großteil der Detailseiten (blau) bekommt sehr wenige Links, allerdings gibt es hier einige Ausnahmen, die sehr viele Backlinks generieren.
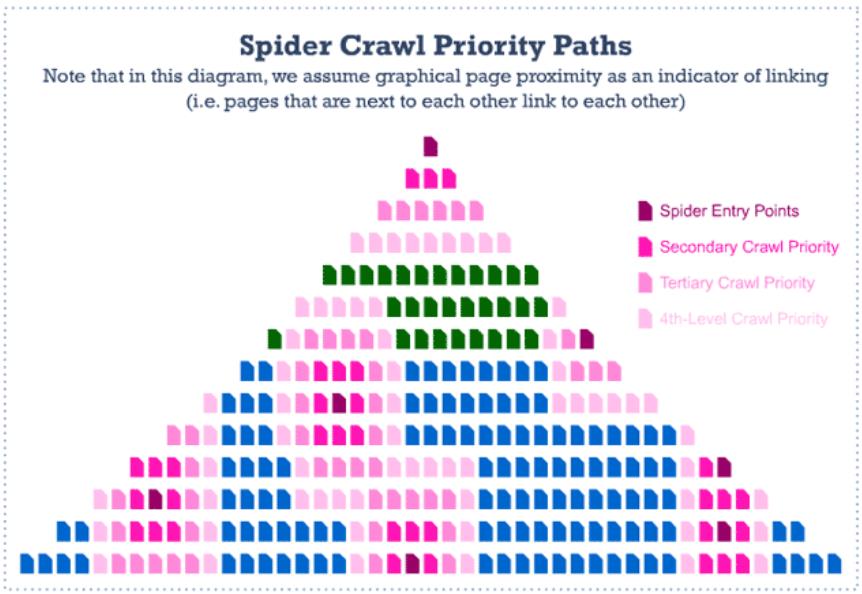
Die zweite Grafik zeigt, wie der Crawler der Suchmaschine solch eine Website crawlt. Eintrittspunkte sind die Seiten, die die meisten Backlinks generieren. Diese geben Linkjuice an die umliegenden Seiten weiter, die dadurch auch recht regelmäßig gecrawlt werden. Viele Seiten werden allerdings gar nicht vom Google-Bot besucht.
So viel zur Veranschaulichung. Hier nun einige Tipps zur Gestaltung der Informationsarchitektur und der internen Verlinkung:
- Die Informationsarchitektur möglichst flach halten, sodass jede Unterseite mit möglichst wenigen Klicks erreichbar ist.
- Seiten mit vielen Backlinks intern mit solchen verlinken, die mehr Linkpower brauchen. So werden diese Seiten gestärkt und öfter gecrawlt.
- Die wichtigsten Seiten in der Nähe zur Homepage platzieren. Diese gibt nämlich in der Regel am meisten Linkjuice weiter.
- Die wichtigsten Seiten sollten am öftesten intern verlinkt sein. Auch das hat direkte Auswirkungen auf das Crawl-Budget für diese Seiten.
- Neben der Homepage sollten auch Kategorieseiten durch mehr externe Links gestärkt werden. Diese können PageRank und Linkjuice und somit auch Crawl-Budget weiter in die Website hineinlenken. So sieht Google, dass alle Unterseiten wichtig sind und nicht nur die Homepage und einige einzelne Detailseiten.
- „Unendliche“ Crawl-Pfade sollten vermieden werden. Diese können z.B. bei Kalendern mit Links zu Hunderten von Events entstehen.
Technik zur Optimierung des Crawlings
Nachdem durch eine gut strukturierte Informationsarchitektur der Grundstein für die Crawl Optimization gelegt wurde, kommen wir nun auf die technischen Aspekte zu sprechen, mit deren Hilfe man dem Google-Bot mitteilen kann, wie er eine Website auslesen soll. Das Robots Exclusion Protocol wurde vor einiger Zeit bereits auf unserem Blog thematisiert. Dazu zählen die robots.txt, Metadaten, Sitemaps und Mikroformate, mit deren Hilfe man den Crawlern Anweisungen geben kann, wie sie sich auf einer Website verhalten sollen.
robots.txt
Mithilfe der robots.txt kann ein Webmaster festlegen, ob bestimmte Unterseiten, einzelne Verzeichnisse oder sogar die gesamte Website vom Crawling ausgeschlossen werden sollen. Der Suchmaschinen-Crawler hält sich in der Regel an die Anweisungen der robots.txt und wird dementsprechend kein Crawl-Budget für die ausgeschlossenen Seiten verwenden. Sinnvoll ist das zum Beispiel bei Kontaktformularen oder Login-Seiten, die vom Bot ohnehin nicht ausgefüllt werden können. Auch ist es möglich, spezielle Suchmaschinen-Crawler wie zum Beispiel den Google-Bot für Bilder von der Website auszuschließen.
Wichtig: Der Ausschluss einer Unterseite in der robots.txt ist keine Garantie dafür, dass diese nicht im Index auftaucht. Hält Google die Seite für wichtig, kann sie trotzdem in den SERPs erscheinen.
Wie man eine robots.txt erstellt, könnt ihr im Artikel robots.txt – so wird’s gemacht nachlesen.
Metadaten
Eine zweite Möglichkeit zur Crawler-Steuerung sind die Meta-Tags. Während in der robots.txt auch ganze Bereiche der Website vom Crawling ausgeschlossen werden können, beziehen sich die Meta-Angaben immer nur auf eine einzelne Seite und müssen dementsprechend bei jeder Seite einzeln eingefügt werden. Meta-Tags können praktischerweise sowohl in HTML-Dokumenten als auch in http-Headern (bei PDFs, Bildern, etc.) eingebaut werden.
Die wichtigsten und wohl auch bekanntesten Meta-Tags sind noindex und nofollow:
- noindex: Damit teilt man der Suchmaschine mit, dass die Seite nicht indexiert werden soll.
- nofollow: Hierdurch weiß der Crawler, dass er den Links auf der Seite nicht folgen soll.
In der Praxis sieht das Ganze zum Beispiel so aus:
<meta name="robots" content="noindex, nofollow"/>
Die Angaben in den Meta-Tags sind für den Google-Bot bindender als diejenigen in der robots.txt. Möchte man also sicher gehen, dass eine Seite tatsächlich nicht in den Index gelangt, sollte man auf die Meta-Tags zurückgreifen. Das ist die sicherere Alternative, da man so dem Bot explizit mitteilt, dass eine Seite nicht in den Index aufgenommen werden soll.
Um die Meta-Tags auslesen zu können, muss Google die Seite zunächst crawlen. Durch das Meta-Tag noindex wird also Crawl-Budget beansprucht, jedoch kein Index-Budget.
Außerdem gilt es, darauf zu achten, dass eine Seite nicht gleichzeitig via robots.txt ausgeschlossen und mittels Meta-Tag auf noindex gesetzt wird. Dann wird der Crawler die Seite nämlich gar nicht erst auslesen und hat keine Möglichkeit, an die noindex-Information aus den Meta-Daten zu kommen.
Sitemaps
XML-Sitemaps präsentieren dem Crawler der Suchmaschine die URLs einer Website als Liste. Somit kann die Suchmaschine schnell alle in der Sitemap aufgeführten Unterseiten erfassen. Das Crawlen der Seite ist somit leichter und die Struktur der Website wird vom Google-Bot schneller erkannt. Außerdem wird sichergestellt, dass der Crawler wirklich alle Unterseiten der Domain finden kann. Für multimediale Inhalte wie Videos und Bilder kann es sinnvoll sein, jeweils eine zusätzliche Sitemap anzulegen.
Damit Google möglichst schnell auf die Sitemap aufmerksam wird, kann es sinnvoll sein, den Speicherort der Sitemap in der robots.txt anzugeben.
Mikroformate
Mikroformate dienen dazu, Inhalte für Suchmaschinen mit zusätzlichen Informationen auszuzeichnen, sodass sie von den Suchmaschinen besser interpretiert werden können.
Im Zuge der Crawl-Optimierung ist vor allem das rel=nofollow-Attribut für Links interessant. Damit kann dem Crawler mitgeteilt werden, dass er einen bestimmten Link ignorieren und ihm somit nicht folgen soll. In der Praxis sieht das so aus:
<a href="http://beispiel.de/" rel="nofollow">Anchor-Text</a>
Monitoring mittels Server Logfiles
Wann immer man einen Aspekt einer Website optimieren möchte, ist auch ein Monitoring unabdingbar, um mögliche Fehlentwicklungen und Erfolge schnellstmöglich aufzudecken. SEOs nutzen hierfür zahlreiche Tools wie zum Beispiel die Google Webmaster Tools und Google Analytics, die bereits eine Vielzahl an Informationen darüber bieten, wie die verschiedenen User die Website nutzen.
Will man im Zuge der Crawl Optimization jedoch richtig in die Tiefe gehen und die Crawler der Suchmaschinen tracken, reichen diese Daten oft nicht aus. Dann bietet es sich an, die sogenannten Server Logfiles auszuwerten.
Server Logfiles sind detaillierte Berichte über verschiedenste Website-Zugriffe, in denen jede Aktion der User festgehalten wird. Das gilt nicht nur für Menschen, die die Website besuchen, sondern auch für sämtliche Crawler und Bots. Somit geben sie vollständig wieder, wie häufig ein Suchmaschinen-Crawler eine Website besucht, wie er sich auf der Website verhält, welche Crawl-Pfade er wählt und welche Unterseiten er ausliest.
Analysiert man diese Daten, lassen sich Rückschlüsse auf mögliches Optimierungspotenzial ziehen. Stößt ein Crawler beispielsweise besonders häufig auf 404-Fehlerseiten, so ist das ein eindeutiges Indiz für verschwendetes Crawl-Budget.
Die folgenden zwei Artikel befassen sich ausführlich mit dem Thema Logfile-Analyse und ihrem Nutzen für die Suchmaschinenoptimierung:
SEO Finds in Your Server Logs, Part 2: Optimizing for Googlebot
Ich hoffe, ich konnte euch einen Überblick über die Grundzüge der Crawl Optimization geben und freue mich auf regen Austausch in den Kommentaren.
Wir wünschen euch noch eine schöne Restwoche!
Amke und die SEO Trainees





24 Antworten
Ist zwar schon etwas alt, aber immer noch den heutigen Standards entsprechend. Mich würde mal interessieren, was sich zu heute geändert hat.
Servus Amke,
sehr interessant Dein Artikel. Ich hätte dazu eine Frage, seit ca. 1 Jahr finde ich wird meine Webseite sehr schlecht gecrawlt, und ich habe bis heute nicht herausgefunden, an was es liegt. Egal ob ich täglich einen Artikel veröffentliche oder 1x pro Woche, Google ändert meine Seiteninhalte nur alle 2-3 Wochen. Was kann daran schuld sein? lg. Walter
Hallo Walter,
das lässt sich so pauschal leider nicht genau sagen, da der Crawl-Prozess algorithmisch ist.
Allgemein ist z. B. eine flache Seitenstruktur von Vorteil, zudem sollten die Seiten intern miteinander verlinkt sein, damit der Crawler sie einfacher findet. Außerdem solltest sicherstellen, dass der Speicherort deiner Sitemap in der robots.txt angegeben und dass die Sitemap richtig angelegt ist.
Viele Grüße
Kira
Sehr Interessanter Beitrag. Ich habe bereits vor ein paar Tagen einen sehr auführlichen Artikel über eine Fachmesse erstellt und veröffentlich. Leider fehlt mir hierzu noch das Google Ranking.
Hallo Amke,
wunderbarer Artikel. Danke dafür. Was ich allerdings nicht nachvollziehen kann, ist das Index-Budget. Ich konnte hierzu bei meinen Recherchen bis dato nichts finden. V.a. keine Aussage von Google. Lediglich Aussagen von Matt Cutts, dass Google den PageRank als Kennzahl für das Crawlbudget verwendet, welches einer Domain zuteil wird… Wo hast du die Info über das Index-Budget gefunden?
LG
Tobias
Hallo Tobias,
da Amkes Traineezeit schon vorbei ist, übernehme ich mal die Antwort.
Also, so etwas wie Crawl Budget oder Index Budget gibt es nicht wirklich. Es ist eher eine bildliche Umschreibung für die Tatsache, dass die Suchmaschine nicht von jeder Seite alle Inhalte indexiert und jede Unterseite crawlt. Das steht auch in dem „Matt Cutts„-Link.
Viele Grüße
Tobias
Die beste Zusammenfassung, die ich zu dem Thema je gelesen habe. Gerade bei sehr umfangreichen Webauftritten wie z.B. einem Forum wie ich es betreibe, ist das Trennen von wichtigen und unwichtigen Content sehr wichtig.
Dabei ziehe ich es auch vor mit Metadaten zu arbeiten, anstatt mit einer robots.txt
Das Gute dabei ist ja, dass man mit noindex,follow den Bot trotzdem weiterschicken kann zu wichtigem Content, der von unwichtigen Seiten intern verlinkt ist, die nicht im Index landen sollen. Mit der robots.txt ist das so ja leider (noch) nicht möglich.
Ein sehr leidiges Thema. Gerade wenn man beginnt eine Webseite zu betreiben. Die Zeit die man für google benötigt wird länger als die eigentliche Entwicklung.
Aber sehr schön das dies so schön zusammengefasst wurde.
Lg Lena
Es ist schon merkwürdig. So richtig habe ich noch nicht rausgefunden was es wirklich ausmacht. Mal ja, mal nein. Und am nächsten Tag ist alles wieder ganz anders. Mmmhh? Probieren wir halt weiter.
Danke für die Info.
Martin
Sehr schöner Artikel. Ich finde auch es ist auf jeden Fall wichtig, dass man sich im SEO auch direkt am Anfang die Crawlbarkeit einer Webseite anschaut. Denn hier muss es zunächst eine solide Basis geben.
Hi Martin,
danke für deinen Kommentar. Ich stimme dir zu – die Crawlbarkeit und die Informationsarchitektur einer Website sind grundlegende Aspekte, die gleich zu Anfang Beachtung finden sollten. Darauf lassen sich dann wunderbar tolle SEO-Strategien aufbauen.
Beste Grüße,
Amke
Also um sich so etwas zu kümmern finde ich unnötig wie ein Kropf, habe Webseiten mit mehreren tausend Unterseiten und noch nie Probleme damit gehabt. Google indexiert heutzutage ohne jedes Zutun einfach alles.
Hallo Andy,
danke für deinen Kommentar. Ich denke schon, dass es sinnvoll sein kann, bestimmte Seiten von der Indexierung auszuschließen, auch wenn der Nutzen sicher von Website zu Website unterschiedlich groß ist. Für Google betrachtet solche Angaben in der Regel nicht als verpflichtend, also kann es natürlich sein, dass Inhalte trotzdem indexiert werden, auch wenn man sie ausgeschlossen hat. Ich denke aber, grundsätzlich kann es nie schaden, solche Möglichkeiten der Kommunikation mit Google zu nutzen.
Beste Grüße,
Amke
Sehr guter Bericht! Muss ich gleich mal teilen..
Gut mal zu wissen, wie der Google Crawler wirklich funktioniert.
Ein paar Techniken waren mir mir und deswegen bedanke ich mir für den super Beitrag. Danke nochmal für den Tipp mit der Sitemap, hatte den zwar im Kopf hab aber leider nicht wirklich dran gedacht.
Sehr gerne! Freut mich, dass dir die Tipps weiterhelfen! 🙂
Toller Artikel, danke. Bei der Suchmaschinenoptimierung auch auf die Crawl Optimierung zu schauen ist neu für mich. Mal schauen was sich da noch rausholen lässt.
Hallo Jens,
gern geschehen – ich freue mich, dass der Artikel dir gefällt.
Grüße,
Amke