Was sind eigentlich sogenannte Crawler Traps und wie lassen sie sich erkennen und vermeiden? Dies und mehr erfahrt Ihr in unserem neuen Wochenrückblick.
Wie sich Crawler Traps identifizieren und vermeiden lassen
Zu verstehen, wie Suchmaschinen arbeiten, ist ein fundamentaler Teil der Suchmaschinenoptimierung. Das Crawlen und Indexieren von Websites durch Crawler, wie dem Google Bot, ist der Startpunkt dieses Prozesses und sollte daher sehr genau betrachtet werden. Wenn bereits in dieser essentiellen Phase des Crawlings Fehler auftreten, ist der gesamte weitere Prozess der Indexierung gefährdet, der schlussendlich benötigt wird, um von Suchmaschinen indexiert zu werden und damit die Chance zu erhalten, ein gutes Ranking zu erzielen. Doch was genau kann bei dem Crawling-Prozess schieflaufen und welche Aspekte müssen beachtet werden. Ein wichtiges Thema in diesem Zusammenhang sind die sogenannten Crawler Traps. Was diese „Fallen“ für Crawler sind und was Ihr zu diesem Thema unbedingt wissen solltet, möchten wir Euch im heutigen Top-Thema vorstellen. Diesen Artikel haben wir auf zwei Beiträgen von Search Engine Journal und Content King aufgebaut. Dort findet Ihr auch interessante und vertiefende Informationen zum Thema.
Was sind Crawler Traps?
Eine sogenannte Crawler Trap entsteht, wenn ein Crawler, also zum Beispiel der Google Bot, auf ein strukturelles Problem einer Website trifft, was verursacht, dass der Crawler in eine Endlosschleife verfällt und eine Vielzahl an irrelevanten URLs crawlt, die zu keinem neuen Content führen. Es besteht also die Möglichkeit, dass der Crawler in einem Abschnitt einer Website hängen bleibt und das Crawlen dieser irrelevanten URLs nicht beenden kann.

Aber warum sollte man sich überhaupt Gedanken über solche Crawler-Fallen machen? Das größte Problem der Crawler Traps ist das Aufbrauchen des Crawl Budgets. Unter Crawl Budget wird hierbei die Anzahl der Seiten verstanden, die ein Suchmaschinen-Bot gewillt ist, zu crawlen, bevor dieser von der Website abspringt. Wenn Crawler Traps also verursachen, dass der Crawler viele für SEO irrelevante Seiten crawlt, wird das Budget dadurch unnötig verbraucht und der Crawler kann sich nicht auf die wichtigen Seiten der Website konzentrieren. Crawler haben zwar die Fähigkeit solche Fallen zu erkennen, dafür gibt es jedoch keine Garantie. Des Weiteren müssen Crawler erst in die Falle tappen, um diese zu bemerken, was natürlich wiederum Crawl Budget verbraucht. Wenn Ihr selbst sicher gehen wollt, dass Ihr keine Nachteile durch diese Fallen erfahrt, solltet Ihr selbst erkunden, was aktiv dagegen getan werden kann.
Welche Crawler Traps gibt es?
Nun stellt sich selbstverständlich die Frage welche Arten von Crawler Traps es überhaupt gibt und welche Eigenschaften sie besitzen, um zu entscheiden, wie diese behoben werden können. Im Folgenden haben wir einige ausgewählte Möglichkeiten für Euch zusammengetragen.
URLs mit Parametern
Eine erste Gefahr können Parameter einer URL darstellen. Diese sollten für Suchmaschinen nicht zugänglich sein. Parameter werden normalerweise dafür verwendet, um bestimmte Informationen wie Produktfilterkriterien oder Session IDs aufzubewahren. Die untenstehende Abbildung zeigt Euch, wie dies an einem konkreten Beispiel aussieht. Wenn also zum Beispiel eine URL mit Filterkriterien gelesen wird, kann das dazu führen, dass sehr viele verschiedene URLs mit unwichtigem Content indexiert werden. Dieses Phänomen ist vor allem bei Produktfiltern vorzufinden. Denn während Nutzer nur ein paar verschiedene Filter anwenden, gehen Crawler jeder möglichen Kombination dieser Links nach. Mit Hilfe der Google Search Console kann Google mitgeteilt werden, wie mit Parametern umgegangen werden soll.

Weiterleitungsschleifen
Ein weiteres Problem sind lange Weiterleitungsketten beziehungsweise Weiterleitungsschleifen. Meistens entstehen diese durch Fehler im Code und können eine enorme Menge an Crawl Budget verbrauchen. Wenn beispielsweise alle Anfragen nach URLs ohne Trailing Slash, mit Hilfe einer 301-Weiterleitung auf die URL mit Trailing Slash führen, durch einen Fehler diese aber wiederum auf die URLs ohne Trailing Slash weitergeleitet werden, entsteht eine Weiterleitungsschleife. Diese „Falle“ kann durch die Prüfung der Weiterleitungsstruktur einer Website behoben werden.
Links zu internen Suchergebnissen
Um weiteren Content zu kreieren, verwenden manche Websites die Verlinkung zu internen Suchergebnissen, das bedeutet, dass überwacht wird, welche die beliebtesten internen Suchanfragen sind, um daraufhin von inhaltlichen Seiten auf solche zu verlinken, da sie als hilfreich für den User angesehen werden. Diese können jedoch entweder sehr wenige oder sogar gar keine Ergebnisse beinhalten, was wiederum dazu führt, dass Seiten mit schwachen Inhalten gecrawlt und indexiert werden können. Dieses Vorgehen sollte daher, wenn möglich, vermieden werden.
Integrierte Kalender
Diese Crawler Trap ist womöglich eine der am einfachsten nachzuvollziehenden Varianten. Seiten, auf denen ein Kalender zu finden ist, haben das Potenzial Crawler dadurch aufzuhalten, dass sie eine Vielzahl an zu crawlenden Links haben, die auf die nächsten Monate verweisen. Dabei wird das jeweilige Datum oft in die URL gesetzt und die Daten reichen meist weit in die Zukunft.
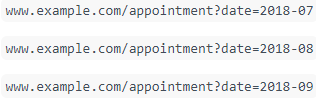
Diese sind aus SEO-Sicht generell uninteressante Inhalte, die schlecht für das Crawl Budget sind. Es ist daher sinnvoll darauf zu achten, Kalender nicht zu weit in die Zukunft laufen zu lassen, die Link-Attribute „Nächster Monat“ und „Vorheriger Monat“ auf nofollow zu setzen oder auch durch die robots.txt-Datei den Crawlern mitzuteilen, dass diese URLs nicht gecrawlt werden sollten.
Relative Links
Ein relativer Link ist ein Link, welcher das Ziel der URL nicht durch eine komplette (absolute) URL anzeigt, sondern die Zielressource abhängig von der Domain und dem Verzeichnis anzeigt, was auf Unterseiten der Website verweist. Doch in dieses URL-Format können sich leicht Fehler einschleichen, die sich zu einer Crawler Trap entwickeln können. Der häufigste Fehler ist hierbei das Ausbleiben des ersten Schrägstriches der relativen URL. In der folgenden Abbildung wird deutlich was es für Auswirkungen haben kann, wenn der Crawler die relative URL in eine absolute umwandelt. Die erste Zeile zeigt die korrekte absolute URL. Als nächstes wird die relative URL mit dem fehlenden Schrägstrich gezeigt. Die nächste Zeile stellt die Umwandlung der relativen zur absoluten URL dar, die durch den Crawler durchgeführt wird. Wenn man nun die letzte Zeile mit der richtigen absoluten URL in der ersten Zeile vergleicht, wird deutlich, dass ein Fehler aufgetreten ist.
![]()
![]()
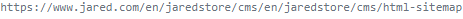
Falls der Crawler hier nun keinen 404-Fehler erhält, versucht er weiterhin die URL zu crawlen und landet so in einer Schleife, die ihn nie zu der korrekten Seite führt.
Um diese Fehler zu entdecken, kann ein eigener Crawl der Seite durchgeführt werden. Eine weitere Möglichkeit ist es, in den eigenen Server-Protokolldateien nach langen URLs Ausschau zu halten.
Crawler Traps erkennen und vermeiden
Optimal sollten Crawler Traps schon in der Entwicklungsphase entdeckt und behoben werden, sodass die besprochenen Probleme erst gar nicht entstehen. Da es jedoch oft nicht realistisch ist, alle möglichen Fallen schon im Voraus aufzudecken, müssen die Probleme meist im Nachhinein behandelt werden. Wir haben hier ein paar Punkte aufgeführt, die im Allgemeinen helfen, Crawler Traps zu erkennen.
- Einen eigenen Crawl durchführen: Eine Möglichkeit Crawler Traps zu finden, besteht in der Durchführung eines eigenen Crawls. Hierbei sollte bei der Betrachtung der URLs auf Parameter, sich wiederholende Muster innerhalb der URLs sowie Seiten mit doppelten Titles, Meta Descriptions und Headings geachtet werden.
- Erweiterte Suchoperatoren nutzen: Auch erweiterte Suchoperatoren können dazu verwendet werden, Crawler Traps zu identifizieren. Hier seht Ihr ein paar Beispiele, wie so eine Suchanfrage aussehen könnte: Der Operator „site:“ steht dabei dafür, dass nur innerhalb einer bestimmten Domain gesucht werden soll und „inurl:“ dafür, dass nur Seiten mit bestimmten URL-Mustern interessant sind. Wenn hier viel zu viele Seiten indexiert sind, ist man höchstwahrscheinlich auf eine Crawler Trap gestoßen.
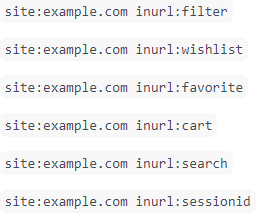
- Weitere Optionen sind die Überprüfung von URL-Parametern im Abschnitt Crawl > URL Parameter in der Google Search Console sowie die Analyse der Protokolldateien des Webservers, um gewisse URL-Muster zu erkennen, die auf eine Crawler Trap hinweisen.
Fazit
Um im Bereich der Suchmaschinenoptimierung erfolgreich zu sein, bedarf es unter anderem eines grundlegenden Verständnisses für die Arbeitsweise von Suchmaschinen. Wenn diese entscheidenden Elemente nicht im Blickfeld des Webmasters liegen, können gravierende Fehler entstehen, die sich negativ auf das Ranking der eigenen Website auswirken können. Crawler Traps sind eines dieser Probleme und stellen ein fundamentales Thema in Sachen Websiteoptimierung dar. Hierbei gibt es eine Vielzahl an unterschiedlichen Varianten, wie diese Fallen für Crawler zum Vorschein kommen können, wie zum Beispiel durch Parameter in URLs, Weiterleitungsschleifen oder auch falsche relative Links. Um selbst aktiv zu werden und diese Probleme zu vermeiden, können eigene Crawls durchgeführt oder auch erweiterte Suchoperatoren genutzt werden.
Wir hoffen, dass wir Euch mit diesem Beitrag einen Einblick in das Thema der Crawler Traps ermöglichen konnten und wünschen Euch viel Erfolg bei der Umsetzung unserer Tipps.
Google News
-

Beispiel wie ein 3D-Bild mit Hilfe von Augmented Reality in die Umgebung integriert werden kann. © Screenshot seo-trainee.de Neues zum Thema Bilder-SEO von der Google Entwicklerkonferenz I/O 2019: Schon in unserem Wochenrückblick KW 18/19 haben wir ausführlich darüber berichtet, wie Ihr Euere Bilder für SEO optimieren könnt. Nun veröffentlichte die Website Search Engine Roundtable einen Artikel zu weiteren neuen Features in Sachen Bilder-SEO, die auf der Google I/O vorgestellt wurden und in die Google-Bildersuche integriert werden sollen. Drei Meldung waren dabei besonders interessant: In der Google-Bildersuche soll es bald möglich sein, Google hochauflösende Bilder zu bieten, um dem Nutzer eine bessere Erfahrung ermöglichen zu können. Des Weiteren wird es laut John Mueller bald die Möglichkeit geben, von Bildern in der mobilen Google-Suche durch Swipen des Bildschirms nach oben die dazugehörige Website (AMP-Format) zu sehen und somit auch durch Bilder mehr Interaktion mit der eigenen Website zu ermöglichen. Dieses Feature wird auch in einem Artikel von Upbuild erwähnt, welcher genauer auf die Möglichkeiten eingeht, wie man mit seinen Bildern in die Featured Snippets gelangt. Als Drittes wurde die zukünftige Einführung von 3D-Bildern vorgestellt. Hierbei soll es möglich werden 3D-Bilder zu betrachten und sie dann auch mit Hilfe von Augmented Reality durch die Kamera des Smartphones in bestimmten Umgebungen zu platzieren.
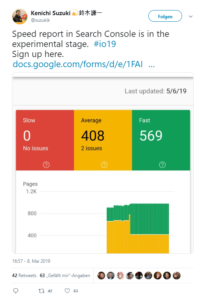
- Der neue Speed Report für die Google Search Console: Ebenfalls auf der Google I/O 2019 bekannt gegeben wurde ein neuer Speed Report für die Google Search Console. Auf Twitter wurden daraufhin die ersten Screenshots des neuen Reports gepostet. Der neue Speed Report soll laut Search Engine Journal dabei helfen, zu erkennen, welche Seiten wie schnell laden und spezifische Probleme von einzelnen URLs bezüglich der Ladegeschwindigkeit zu analysieren. Solltet Ihr Interesse haben, dieses Tool schon vor der Veröffentlichung einmal auszuprobieren, gibt es die Möglichkeit, sich für die bestehende Beta-Version anzumelden.
- Strukturierte Daten für FAQs & How-tos: Strukturierte Daten sind ein wichtiges Thema, wenn es darum geht, dem Google-Bot zu helfen, Inhalte auf einer Website zu verstehen. Nun ist es möglich auch seine FAQs und How-to-Anleitungen mit strukturierten Daten auszustatten, um die Wahrscheinlichkeit zu erhöhen, dass diese in die jeweiligen Rich Snippets beziehungsweise im Google Assistant angezeigt werden. Um dies in die Realität umsetzen zu können, stellt Google sowohl für How-tos als auch für FAQs genaue Informationen zur Umsetzung bereit. Dies zeigt noch einmal auf, wie wichtig die Anwendung von strukturierten Daten ist, um beispielsweise in Bezug auf Rich Snippets sich mit seiner Website erfolgreich durchzusetzen.
- Veränderte Bewertungskriterien in Google PageSpeed Insights: Wie SEO-Südwest berichtet, hat Google Pagespeed Insights nicht nur sein Design geändert, sondern auch die Art wie einige Daten bewertet werden. Veränderungen sind hier zum Beispiel die Minderung der Verzögerungszeit im globalen Suchkontext. Dies kann sich positiv auf den PageSpeed-Score auswirken. Des Weiteren wird die Berechnung des First Content Paints sowie die Daten, die sich auf Progressive Web Apps beziehen, genauer. Zuletzt wird auch die Erfassung von asynchronen JavaScript-Aufrufen verbessert.
Vermischtes
- Was Ihr unbedingt bei der Erstellung eines Title-Tags vermeiden solltet: Search Engine Journal hat einen neuen Beitrag in seiner Reihe „Ask an SEO“ veröffentlicht. Das Thema diesmal: Was ist bei Title-Tags zu beachten und was sollte besser vermieden werden, wenn dieser erstellt wird. Zu diesem Thema wird eine Nutzerfrage beantwortet, die sich um das Thema dreht, welche Inhalte für den Title-Tag sinnvoll sind. Wenn Ihr mehr wissen wollt, schaut doch einfach mal bei Search Engine Journal vorbei.
- Instagram Stories & TV – hilfreiche Tipps zur sinnvollen Nutzung: Seid Ihr auch fleißig auf Instagram unterwegs und nutzt die Plattform für Eure Marketingzwecke, es fehlt Euch aber an Ideen, wie Ihr Eure Marketingstrategie für Instagram kreativer gestalten könnt? Schaut Euch doch einfach mal die Beiträge von allfacebook.de und t3n an und holt Euch Inspiration. Hier wird sowohl auf die kreative Gestaltung der Instagram Stories als auch auf die Nutzung von Instagram TV für ein gutes Videomarketing eingegangen. Die Tipps reichen von der Diskussion über den zeitlichen Rhythmus und das geeignete Format von Instagram Stories bis hin zu der Nutzung von Text und Grafiken bei Instagram TV.
- Tipps zur Verbesserung der eigenen SEO-Strategie mit Hilfe von User-Generated Content: Wie kann ich User-Generated Content eigentlich nutzen, um meine SEO-Maßnahmen zu verbessern? Dies und mehr beantworten Loren Baker und George Nguyen in ihren beiden Artikeln. Loren Baker geht dabei auf Search Engine Journal konkret darauf ein, wie Nutzerinhalte für ECommerce-SEO von Nutzen sein können. Dabei spricht er über Rich Snippets, Review-Seiten sowie die Nutzung von Käuferbewertungen. George Nguyen geht an das Thema der Nutzerinhalte aus einer allgemeinen SEO-Sicht heran und liefert Euch eine Kosten-Nutzen-Analyse des Themas. Beispielhafte Inhalte des Artikels sind die Themen Spam, Reviews und Möglichkeiten der Kontrolle über derartige Inhalte.
- Was Ihr über Keyword-Kannibalisierung wissen solltet: Ein neuer Beitrag auf seonative.de verdeutlicht, wie wichtig es ist, sich mit Keyword-Kannibalisierung auseinanderzusetzen. Hier wird aufgezeigt, dass Keyword-Kannibalismus, also der Fall, dass Seiten derselben Domain für das gleiche Keyword in den Rankings gegeneinander konkurrieren, für die eigene Website schädlich ist und wie diese Probleme vermieden bzw. behoben werden können. Inhaltszusammenlegung durch 301-Weiterleitung, der „noindex, follow“-Befehl oder auch eine verbesserte Keyword-Zordnung sind unter anderem empfohlene Lösungswege.
Unsere Tipps der Woche
- Ein Fuchs als Wegbegleiter in Google Maps: Seit kurzem steht die ausgiebig getestete Augmented-Reality-Navigation von Google Maps für Pixel-Nutzer zur Verfügung. Bei diesen Tests wurde jedoch nicht nur die Augmented-Reality-Navigation getestet, sondern auch ein kleiner Fuchs als Wegbegleiter für den Nutzer. Dieser wurde mit der aktuellen Version noch nicht ausgerollt, ist aber weiterhin geplant. Er soll nicht nur als Wegweiser fungieren, sondern auch Tipps geben und eventuell interessante Zwischenziele erwähnen. Laut dem Google Watch Blog arbeitet das Team von Google fleißig daran, diese Intelligenz gewährleisten zu können und das Design des tierischen Wegweisers weiter zu verbessern.

- Ein Anruf genügt – WhatsApp-Sicherheitslücke: Wie der Google Watch Blog berichtet, gibt es eine aktuelle Sicherheitslücke bei dem Messenger-Dienst WhatsApp, bei dem ein WhatsApp-Anruf für Hacker ausreicht, um Spyware auf dem Smartphone zu installieren und so die Kontrolle über das mobile Gerät zu erhalten. Dafür muss der Anruf noch nicht einmal von dem Nutzer beantwortet werden. Facebook hat diese Lücke bereits erkannt und stellt durch ein Update sicher, dass dies nicht mehr möglich ist. Nutzer, die also immer noch die WhatsApp Version 2.19.134 für Android bzw. 2.19.51 für iOS auf dem Smartphone haben, sollten so schnell wie möglich das Update durchführen.
- SEO Mythbusting-Serie auf Youtube: In unserem letzten Wochenrückblick haben wir Euch bereits in unseren Tipps der Woche über die geplante Videoreihe zum Thema SEO-Mythen von Google Webmasters informiert. Am 15.05 wurde nun die erste Folge der Mythbusting-Serie veröffentlicht.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Ein schönes Wochenende wünschen Euch
Michelle und die SEO-Trainees




